
Code examples of feature fusion techniques and tower encoders in last half of the blog

In Embedding Based Retrieval(EBR) we create embedding of search query in an online manner and then find k-nearest neighbors of the query vector in an index of our entity embeddings (e.g. E-Commerce product, legal/medical document, Linkedin/Tinder user profile, Music, Podcast, Playlist etc). The query and entity embeddings are learnt from a model based on contrastive learning. While query is normally short text, the matched entity has rich feature space (text, float features, image etc). Irrespective of the business problem and model architecture followed (dual encoder, late interaction etc.), a common challenge faced while developing contrastive learning models is how to encode and fuse features of different modalities to create unified representation of an entity and then transform that using some encoder.
Types Of Retrieval Model Architectures

Dual Encoder or Bi-Encoder [1] architecture creates two tower architecture, where the towers correspond to query embedding encoder and Entity embedding encoder. Finally the similarity between the transformed embeddings are calculated and contrastive loss[2] is used to learn the encoder parameters.
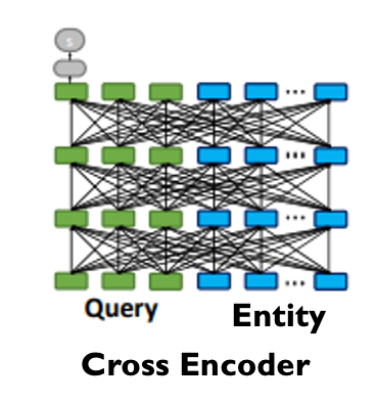
Cross Encoders are Bert[3] or Roberta[4] Encoder style network that performs attention based early fusion between query and entity feature embedding. Although this architecture performs better in similarity tasks (e.g. sentence similarity[5]), due to early fusion these encoders are computationally heavy and inference latency is on the higher end compared to dual encoder based architecture. Due to high inference time latency these encoders are not suited when the candidate set to be compared with query vector is large.
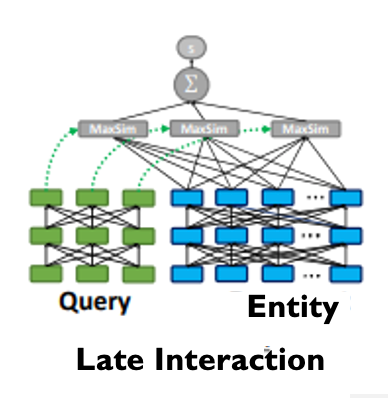
ColBERT[6] adapts deep Language Models (in particular, BERT) for efficient retrieval. ColBERT introduces a late interaction architecture that independently encodes the query and the document using BERT and then employs a cheap yet powerful interaction step that models their fine-grained similarity. By delaying and yet retaining this granular interaction, ColBERT can leverage the expressiveness of deep Language Models while simultaneously gaining the ability to pre-compute document representations cosine, considerably speeding up query processing.
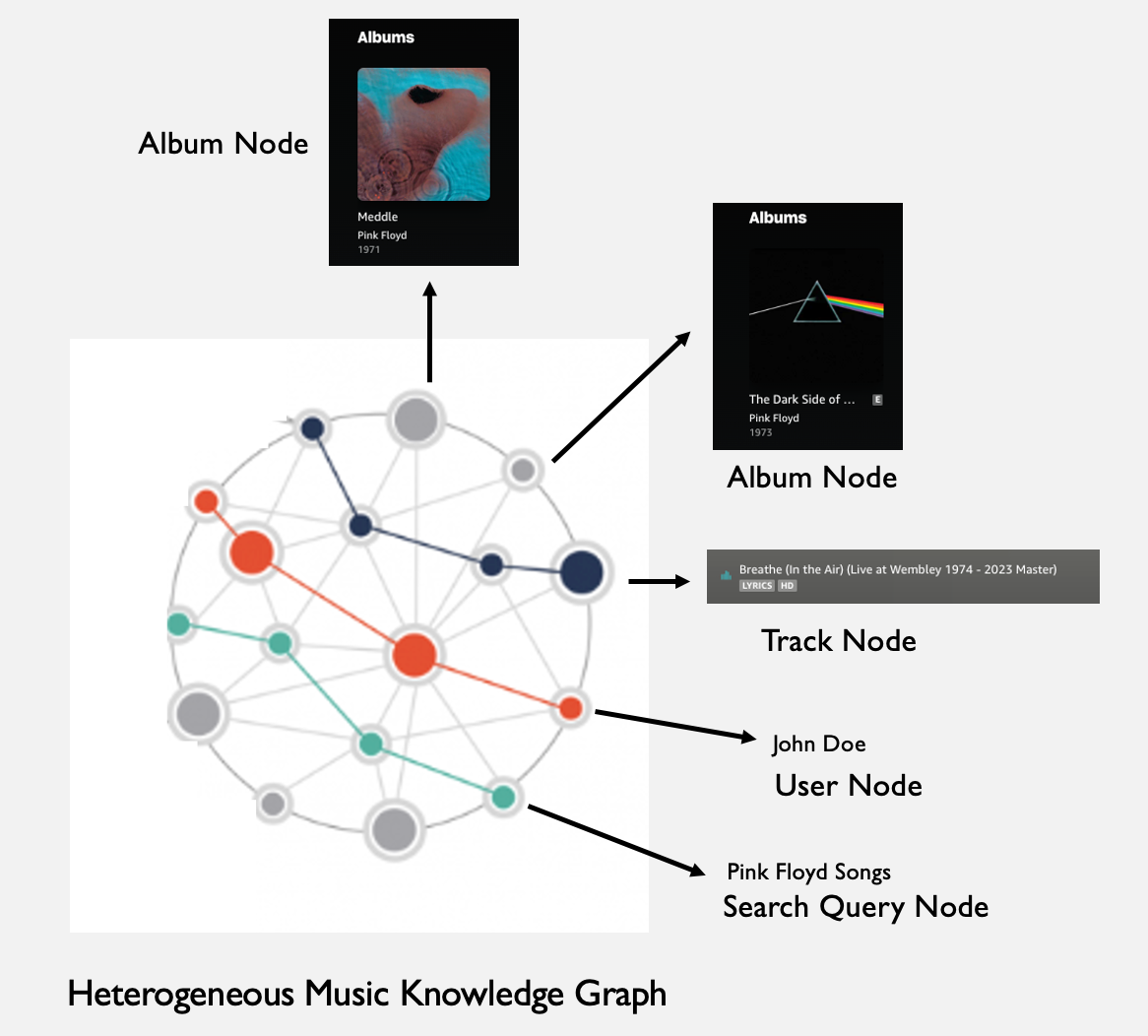
In heterogeneous graphs like the above music graph, we can use graph convolution[7][8] to learn node embeddings based on its local neighborhood.
Generating Initial Entity Embedding From Features
A common problem in all four architectures is how to generate initial entity embedding from its multi modal features. Whether it is e-commerce product, user profile on social media, music track on Amazon Music, a precursor to choosing the model architecture is how to fuse their features together to generate entity embedding (node embedding in the case of graph). Once we have the initial entity representation then we can fine tune it using the architectures discussed above.
How to process and fuse these features to generate unified music album embedding to feed to the entity tower network?

High Level Architecture
Architecture Type : Two Tower / Dual Encoder

1. Input Layer
The input layer will ingest data in the following format.

The above schema helps to standardize the input format and make it agnostic of the domain i.e. whether it is music song, e-commerce product or social media user profile, the features can be stored using the same schema. Features are grouped based on their semantic structure (data type) e.g. all embedding based features will be in embedding_features_map where key would be feature_id/feature_name and value would be feature’s corresponding embedding (float vector).
Types Of Features
- Dense Features
- float value features
- e.g. ctr, number of clicks, frequency of queries etc
- dense_features_map will contain a dictionary where feature is key and corresponding float value will be used as dictionary value
- Category Features
- id based features
- e.g. category id, topic id, user id, podcast id etc
- category_id_features_map will contain feature id is key and corresponding id as value
- Embedding Based Features
- 1 D vector of float values
- e.g. thumbnail image embedding, title embedding, artist/author embedding
- embedding_features_map will be a dictionary of feature id (key) and corresponding vector of floats
- Id List Based Features
- List of ids features
- e.g.
- list of ids of last k songs listened by a user in last ‘x’ hours
- list of ids of last k topics searched by users in last ‘y’ days
- id_list_features_map will be a dictionary of feature id (key) and corresponding list of ids
- [Optional] String Based Features
- string values
- e.g. title, description etc
- string_features_map will be a dictionary of feature id (key) and string as a value
Input layer Module will perform following features
- IO : read input data from s3 or database tables (e.g. Hive or Redshift table)
- Sanity Checks And Validations: e.g. no duplicate feature ids as keys in the input feature maps, data type validations (embedding based features should be float vectors)
- convert the raw data (string, float, vector of floats etc) to respective torch Tensor objects
- Create Dataset and DataLoader objects
2. Feature Encoder Layer
In this layer of the network we would perform pre-processing (standardization, normalization of text and dense features) as well as transform each feature to a vector of floats i.e. their dense representations. This layer would extract features from input layer and transform them using custom encoders (more on that later in this section). Each feature would be encoded separately using end user’s choice of encoder.
Features Of Feature Encoder Layer
- Numerical features scaling, normalization and standardization
- Initialize Embedding matrices (new embeddings to be learned from categorical and id_list_features)
- Encoders
- These will be off the shelf Modules (pre-trained models or learnable PyTorch modules) to transform input features
- e.g. Frozen Bert, SentenceBert, Roberta etc to encode string features to dense representations
- Learnable MLP Encoders to encode dense features or transform other input representations (e.g. transform input embedding feature)
Examples:
Dense Feature Transform
- scale features between 0-1
- Add MLP Encoder (Full connected layer + Non Linearity) to transform dense input features to a fixed length representation
- In the diagram below dense features (integer and float value features) can be
- Music Track popularity
- In the diagram below dense features (integer and float value features) can be
- recency score
- completion rate
- #listens in last k days


String Features Transforms
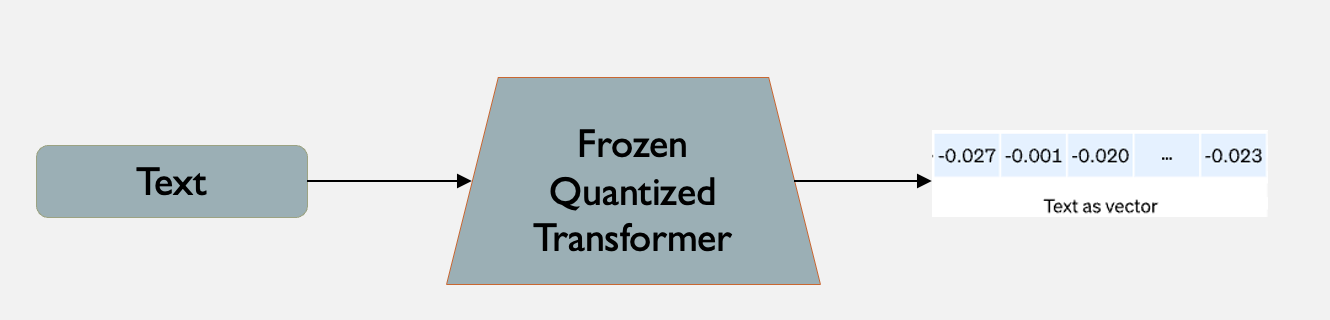
- Given text features we can create representations of text features using pre-trained transformers
- e.g. Text Sequence Encoder (we can make it configurable to use Bert, SentenceBert, Roberta, XLMR etc transformers)

One Hot Encoder:
Genre Encoder or Categorical Encoder : To encode “|” genres into one hot vectors

Identity Encoder
Convert features to Tensors

Categorical Embedding Encoder
- Song Genre to embedding
- Music Band/Artist embedding

Similarly we would have encoders for creating embeddings from categorical ids and id list based features by performing embedding lookup (trainable embedding matrices)
3. Feature Fusion Layer
In this layer we would use custom PyTorch modules to standardize pre-processing of different types of features. This would help ML engineers and Data scientists to speed up model development by using off the shelf boilerplate feature fusion modules.
For details into Feature Fusion please check my earlier blog on Feature Fusion For The Uninitiated
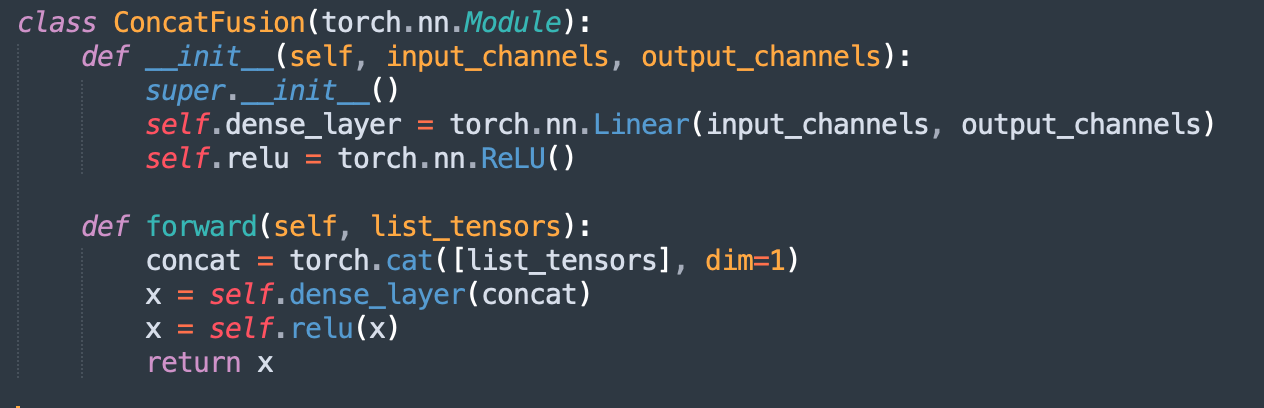
A. ConcatFusion: Concatenate And Transform
- vector-1 : Music Track title text embedding
- vector-2 : Album Embedding
- vector-3: Music Artist embedding

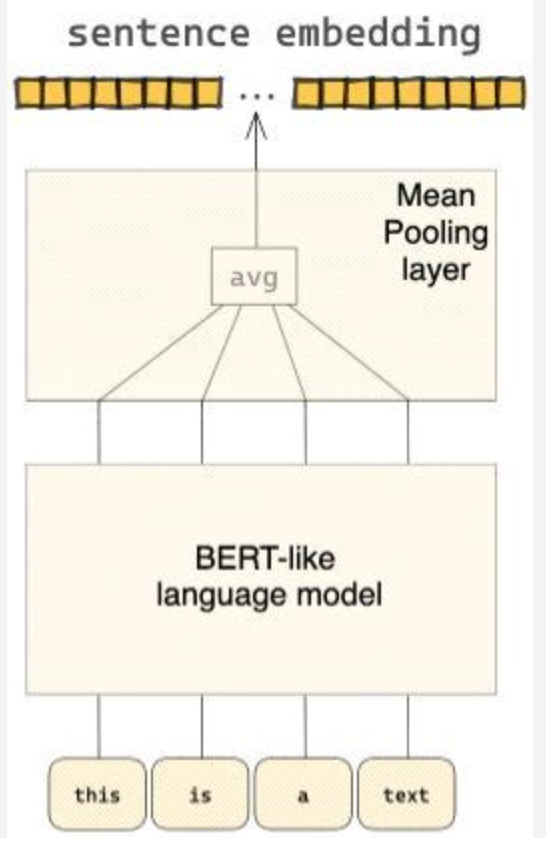
B. PoolingTransform
-
- In pooling transform once you have multiple feature embeddings (of equal length), you perform mean or max pooling to fuse them into one embedding (representing the entity)

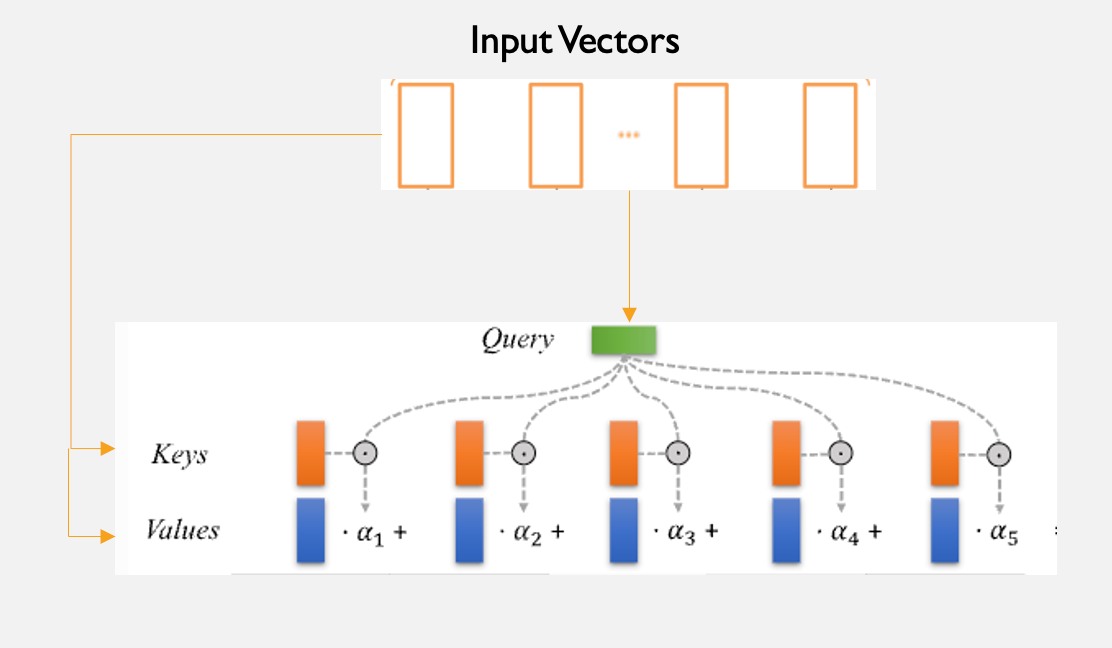
C. AttentionFusion
Attention based fusion applied multi headed attention[9] to the concatenated features vectors.

4.Encoder Layer
In this layer we would provide various kind of encoders that can be easily plugged in the proposed architecture. Query Encoder and Entity encoder will further process the output of feature fusion layer (a single embedding vector).
Some examples of Query/Entity Encoders can be
MLPEncoderTower

class MLPEncoderTower(nn.Module):
def __init__(self, input_dims, number_of_mlp_layers):
super().__init__()
self.mlp_layers = nn.ModuleList(
[MLPEncoder(input_dims, input_dims) for i in range(number_of_mlp_layers)]
)
def forward(self, x):
for mlp_layer in self.mlp_layers:
x = mlp_layer(x)
return xBertEncoderTower
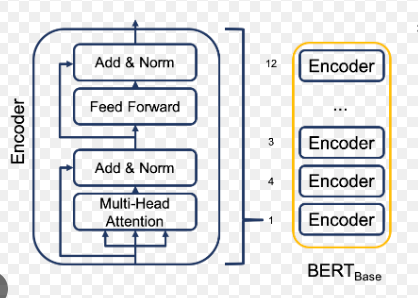
from transformers import BertModel
class BertEncoderTower(nn.Module):
def __init__(self):
super().__init__(device = "cpu", num_layers)
assert num_layers > 0, "number of encoder layers should be greater than 0"
# encoder has only 12 layers
num_layers = min(num_layers, 12)
model = BertModel.from_pretrained("bert-base-uncased")
self.encoder_layers = torch.nn.ModuleList(model.bert.encoder.layer[-num_layers:]).to(device)
def forward(x):
for attention_layer in self.encoder_layers:
x = attention_layer(x)References
- A Deep Relevance Matching Model for Ad-hoc Retrieval
- https://lilianweng.github.io/posts/2021-05-31-contrastive/
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- RoBERTa: A robustly optimized BERT pretraining approach
- https://www.sbert.net/examples/applications/cross-encoder/README.html
- ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT
- Thomas N Kipf and Max Welling. 2017. Semi-supervised classification with graph convolutional networks. In ICLR.
- Will Hamilton, Zhitao Ying, and Jure Leskovec. 2017. Inductive representation learning on large graphs. In NIPS. 1024–1034.
- Attention is all you need
