
Previous post on Attribute Discovery
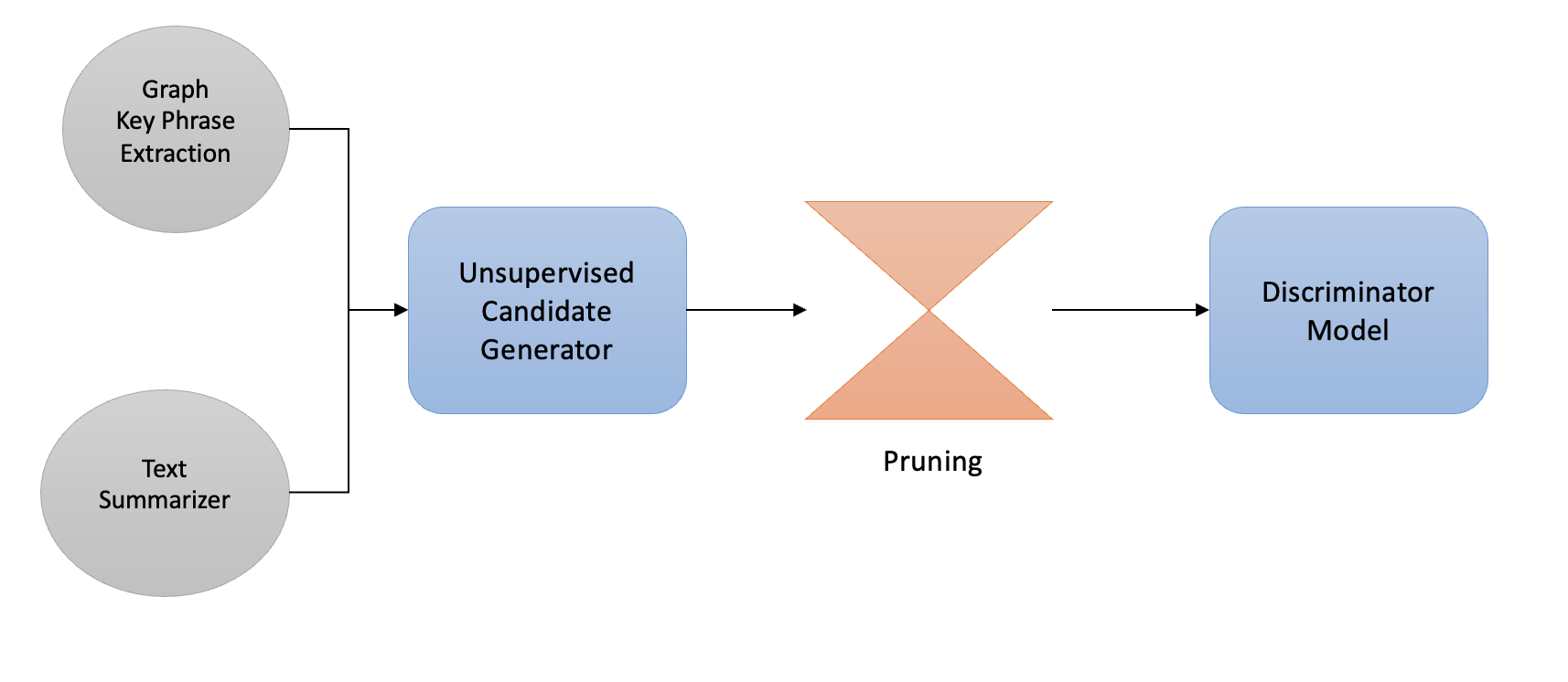
In Part 1 of Attribute Discovery we discussed unsupervised approaches that used Graph based Keyword and Key Phrase extraction algorithms to generate a list of candidate tokens that can be potential attributes missing from e-commerce taxonomy. We furthermore talked about various heuristics like statistical pruning and syntactic pruning based filtering techniques. This article goes one step further to dig into supervised modeling based methods to further remove noisy candidates.
As discussed in the last part of this series, one of the foremost drawback of using a totally unsupervised method for keyword extraction is that we don’t learn from our mistakes once we get feedback on extracted keywords from a Taxonomist or a human labeler. Another issue is that without a model based approach for keyword extraction, we miss out on using approaches like Active Learning that can guide us in creating better training data and hence a better feedback loop to get the contentious data points labeled. The unsupervised keyword extraction techniques are not domain sensitive i.e. they are not tunable to adapt to the data domain or topic and spits out lots of generic keywords that are not important for the domain under consideration. Also the share number of candidates generated are hard to get labeled, so we definitely need a mechanism to rank them in order of importance and get a feedback from domain experts.
Also we are not exploiting the information at hand i.e. attributes that are already part of the taxonomy. Take an example, if we already know that for category Clothing>Kids>Shoes, Color attribute type has values Green, Black And White in our Taxonomy; and candidate generator spits out new candidates as Brown and Blue, we should be able to use the data points already available to us (Green, Black and White) in associating the new keywords (Brown and Blue) to attribute type Color.
After extracting important keywords and candidate brand tokens, we would like to answer following questions
- Whether the new keywords belong to existing attribute types? — Attribute Type Detection
- If not can we group the keywords together so that similar keywords may belong to a new attribute type? — Attribute Type Discovery
To check whether a given keyword belong to a an existing attribute type we try link prediction[1] and node classification[2] based analysis using graph convolutional networks(GCN)[3].

Reference: https://tkipf.github.io/graph-convolutional-networks/
In message passing methodology, in each iteration every node gets messages from neighboring nodes and using their representations (messages) and it’s own representation, a new representation is generated. This involves application of aggregate functions and non linear transformations.

In the above figure node A will receive representations of neighboring nodes B, C and D and after applying linear transformations , permutation invariant aggregation operator (sum, average etc.) and applying further non linear transforms generates a new representation for node A.
These representations are further used for a downstream task like link prediction, node classification, graph classification etc.
Link Prediction[1]
Data :
- Keywords extracted from product title and description of products from Baby & Kids//Strollers & Accessories//Strollers
- Known Attribute Types and their corresponding values in category Baby & Kids//Strollers & Accessories//Strollers i.e. data from the Taxonomy
Heterogeneous Graph Creation
In this approach we first create a graph in which nodes are represented by the extracted keywords and links between them exists if and only if they occurred alongside each other in product title and description text more than a certain number of times. Furthermore we add extra nodes to the graph that represent attribute type e.g. Brand node, Stroller Type Node etc. Additional links were created between the nodes representing the attribute types and their synonyms from the rules table. To make graph dense we added a “pseudo(dummy)” node with category name “stroller”. This node will act as a context node and provide path between existing attribute value nodes (as well as attribute type nodes) and new attribute value candidate (keyword nodes)
Types of Edges
- Brand Node and known brand values
- Stroller Type Node and known stroller type values
- Dummy node “stroller” and keywords occurring in neighborhood of it in product titles and descriptions
- Candidate keywords and rest of nodes occurring in neighborhood of it in product titles and descriptions
Objective : Given two nodes if an edge exist between them. For our use case this would mean given an Attribute Type node e.g. Brand or Stroller Type, whether a link exist between them and candidate keyword.
Node Feature :
Each node has a 100 dimensional feature vector as an attribute. These vectors are word embeddings generated using Fasttext[5].
Category : Baby & Kids//Strollers & Accessories//Strollers

Train/Test Node Tuples
After creating the graph we split the links into train and test dataset. Positive examples include node tuples where edge exists in the graph and for negative examples we created synthetic hard negative examples e.g. tuples created from sample from brand nodes and stroller type attribute values.
Model Architecture

We used Tensorflow based Stellar Graph[4] for creating a 2 GCN layer network with the last layer as binary classification layer. The hidden layer representations of both inout nodes are aggregated using point wise product and the final “edge” representation is forwarded to the binary classification layer. Adam optimizer was used to calculate gradients for back propagation.
Input : word embeddings of tuple of nodes representing an edge e.g. if an edge e is formed by vertices “Brand” and “graco” then word embedding of these two nodes would be input to the node.
Link Prediction Results
The plots below shows the link prediction probabilities on test and train data set.


Attribute Type Prediction And Issues
In the last phase we input node ids for new extracted keywords and Stroller Type attribute node to check if a link exists between them. Similarly we input brand candidates and Brand node id tuples to check if a link exists between the Brand node and new brand candidates. The results of this experiment were really bad as it seems the model is overfitted. Also there is a semantic issue with the links in the graph. One half of edges represent keyword proximity in product title and description whereas other links represent connection between attribute type and synonyms. This discrepancy in the meaning of edges in the graph may be casing issues with low link prediction accuracy on the new data set.
Node Classification[2]
In this second experiment we intend to classify the nodes in the keyword graph to its corresponding attribute type. In this graph each node has an optional attribute representing the class of the node e.g. Brand or other Attribute Type. Graph is formed based on keyword proximity in product title and description text. No additional attribute type nodes are added to the graph like we did in previous link prediction task.
Data:
Category : Toys & Games//Remote Control Toys//Cars & Trucks
- Data Instances : ~16k product titles and descriptions
- Attribute Values and Attribute Types in the Taxonomy for category Cars & Trucks
- as class of the attribute values
Node Features
Each node is represented by 50 dim word embedding generated from Fasttext and 5 dim embedding generated by poincare embeddings from the keyword graph. Poincare embeddings will contain the hierarchical (positional) details of the node in the graph.
Homogeneous Graph Creation
In this graph each node has an optional attribute representing the class of the node e.g. Brand or other Attribute Type. Graph is formed based on keyword proximity in product title and description text. No additional attribute type nodes are added to the graph like we did in previous link prediction task.
Like the earlier experiment we added additional nodes representing known attribute values e.g. known brands and vehicle type etc. To make the graph sufficiently dense, we again added dummy nodes for “car” snd “truck” (tokens in category name). Edges exist only when two tokens occur together in product title or description.

Model Architecture

Visual Analysis
To get visual intuition around effect of training on node representations, we would compare 2D TSNE representations of node feature embeddings before and after training.
Before Training : Train Node Feature Projection In 2D using TSNE

After Training : Train Node Feature Projection In 2D using TSNE

We generate the node representations by feeding the network feature vector of the node (fasttext word embedding concatenated with node’s poincare embedding) and generate the representation from the second GCN layer. (second hidden layer) We can clearly see that in 2D nodes belonging to same attribute type are closer to each other after training the network.
Testing the trained mode on new extracted keywords
In a similar fashion we generate the representation of the newly extracted keywords. The plots below show low dimensional visualization using TSNE of original feature vector of the extracted keywords vs representations generated from trained network.
Plot original feature vectors of keywords with unknown attribute type ( TSNE)
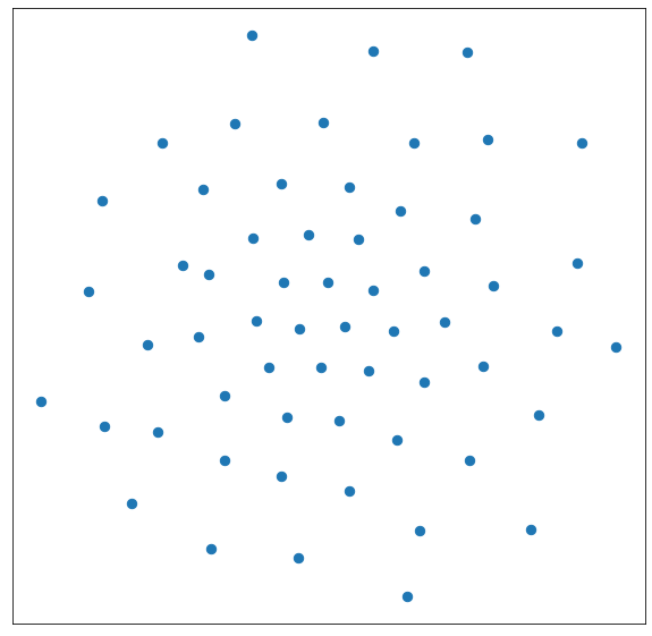
There seems to be no apparent structure in the above plot.
Plot GCN transformed representations of keywords with unknown attribute type (TSNE)

The above plot shows 2 clusters in data, one near the origin and second on the other side of the diagonal.
Node Classification Results
We had 59 keywords where we are unaware of the attribute types.
Threshold Creation
In this step we run the training data through our network and get the max predicted probabilities ie for each node where attribute type is known, classify it using the trained model and select the maximum from the softmax layer.
After that find the 90th percentile from list of output probabilities in the last step. This would be used as classification threshold on data where attribute types are unknown.

Node classification maximum class probability on training data
In the last step the extracted keywords are fed into the network and maximum of softmax layer is compared with the threshold compared in last step. Only when the predicted probability is greater than the calculated threshold than only we would consider the predicted class.
Output :
keyword: run, predicted attribute type: brand
keyword: jeremy, predicted attribute type: rc scale
Both seems to be misclassification.
Hierarchical Clustering the transformed representations of new keywords
After training the model on all the labeled nodes we generated representation of all nodes where class is not available i.e. nodes where we don’t know the attribute type. After that we perform hierarchical clustering on these representations.

It seems three clusters exist in our data. The contents of the clusters are as follows
Cluster 1 = ['kit', 'scale', 'bodied', 'diecast', 'toy', 'red', 'redcat',
'jeremy', 'mayfield']
Cluster 2 = ['rc', 'nitro', 'work', 'model', 'brand', 'custom', 'light', 'rear',
'seat', 'speed', 'ship', 'ford', 'barbie', 'power', 'like', 'race',
'pickup', 'condit', 'baja', 'vxl', 'talion', 'partes', 'black',
'lamborghini', 'look', 'spiderman', 'indy', 'conteol', 'lowrider']
Cluster 3 = ['charger', 'good', 'need', 'box', 'control', 'vw', 'batterie',
'come', 'remot', 'price', 'wheel', 'ride', 'drive', 'atv', 'kid',
'jeep', 'run', 'include', 'tire', 'upgrade', 'motor']
The intuition behind this experiment was that after GCN transformations newly discovered keywords that are similar to each other would group together in one cluster and that cluster may be represented by an attribute type.
Conclusion
We discussed various approaches that don’t solve the problem of attribute extraction individually but as a whole, pipeline comprising of the above steps as individual component can provide us an unsupervised way to generate candidate attribute values and brands that can be further pruned by taxonomists. This approach can save us lot of time by automating the attribute discovery phase and providing not only important keywords/brands but also synonyms present in data that can be further used to increase coverage. The proposed tool is neatly laying down all the relevant information about about every category that the taxonomist needs in form of keywords, brands and attributes.
