
Glimpses On Implicit/Explicit, Dense/Sparse, Gated/Non Gated, Low Rank And Many More Layered Interactions

101 Ranking Model Architecture
Neural ranking models are the most important component in multi stage retrieval and ranking pipeline. Whether it is e-commerce search, ads targeting, music search or browse feed ranking, ranking model will have the final say in selecting the most relevant entity for a given request. Improvement in ranking model’s architecture (as well as feature space) can have a direct impact on boosting the business KPI.
In this post I would discuss brief history of development around ranking model architectures. I woulds show how the core model architecture evolved with each major break-though in neural architecture development.
Part 1 — Genesis
In this section I would quickly go over some early model architectures and would discuss some key issues involved with them.
A. Issues With Wide Only Model

Wide only model (no representation learning) learns weights for individual features and their corresponding interactions. Key issue with this approach is that
- There is no generalization.
- We can’t learn interactions in absence/sparsity of training data
- Shallow Architecture — Single layer model, no feature transformation
B. Factorization Machine, Steffen Rendle, 2010
Given a real valued feature vector x ∈ Rn where n denotes the number of features, FM estimates the target by modeling all interactions between each pair of features
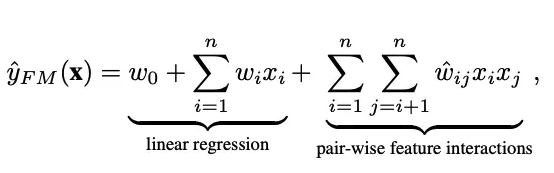
- w0 is the global bias
- wi denotes the weight of the i-th feature
- wij denotes the weight of the cross feature xi * xj
- (factorization) -> wij = vTi vj , where vi ∈ Rk denotes the embedding vector
In this architecture we project sparse features onto low dimensional dense vectors and learn feature interactions. Along with learning weights over individual sparse features (id based features, gender, categories etc), we learn their interactions via pair wise dot product of their representations.
Advantages of Factorization Machines
- Can generalize better
- Can handle sparsity w.r.t training data e.g. even if we have never seen interaction between Age 12 and Ad Category Gaming in training data, at inference time we can learn their interaction value by using corresponding embedding’s dot product
Disadvantages of Factorization Machines
- Shallow Structure — Limited Capacity Model (low representation power)
- Lacks feature transform capability
- Lacks ability to use embeddings based features (we can’t use pretrained embeddings for a feature)
C. Wide & Deep — Poor Man’s Ranking Model

This architecture has two key components, a wide part (dealing with float value and binary features) and a deep part (learns representations of sparse id based features). Wide part focuses on memorization and deep part on generalization. By jointly training a wide linear model (for memorization) alongside a deep neural network (for generalization), one can combine the strengths of both.
Wide Network
- Manually created handcrafted interaction features
- Helps in “Memorization” of important interactions
- No Dense Sparse Interaction — Sparse (embedding) features interact in deep part of the network but they don’t interact with the dense part of the network
- No transformations for the dense feature layer
- Uses FTRL for optimization
Sparse Network
- Fully connected Network
- Uses different optimizer than wide part (AdaGrad)
- No explicit interactions : We have a fully connected network which created implicit interactions between features e.g. we can’t learn explicit interaction between category embedding and user embedding for an e-commerce product to learn user proclivity for that category.
D. Attention Factorization Machines
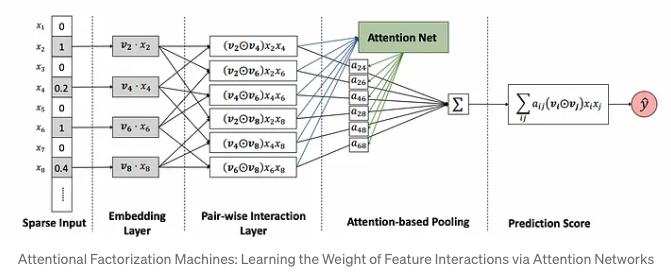
Like factorization machines, this method performs pair wise interactions between representations of features. But to improve over that method it uses attention based pooling mechanism to assign higher weights to most relevant interactions.
E. Deep & Cross — Deep & Cross Network For Ad Click Predictions
This architecture introduces the notion of “explicit” feature interactions.

Implicit Cross (think image representation) : Interaction is learned through end to end function without any explicit formula modeling such cross. The aim is to learn a high level representation e.g. a feature map in CNNs.
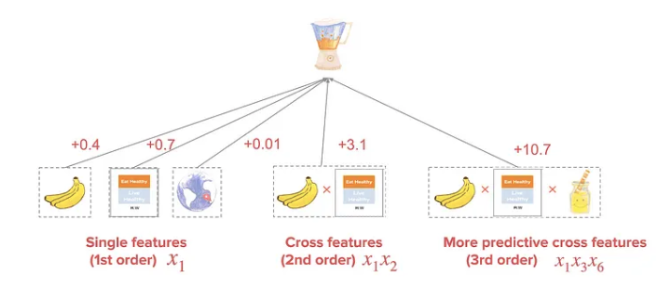
Explicit Cross (think gender * age * music genre interaction) : Modeled by an explicit formula with controllable interaction order. Aim is to learn weights over these explicit feature crosses.

Deep & Cross : Leverage implicit high-order crosses learned from DDNs, with explicit and bounded-degree feature crosses which have been found to be effective in linear models. One part of the network (left part) focuses on creating explicit feature crosses via a controllable function while the other part of the network (right part) is a deep network that learns implicit feature interactions.
Cross Network In Details
In the cross network we use following interaction formula

Here each layer would create interaction between output of previous layer and first layer (input layer), then we add the previous layer output as a residual skip connection. As we add more layers, we would generate higher order explicit interactions. We are learning previous layer’s interactions (layer L)via residual connection and adding more information to it via generating another higher order (L+1) interaction via taking element wise product of input vector with it.
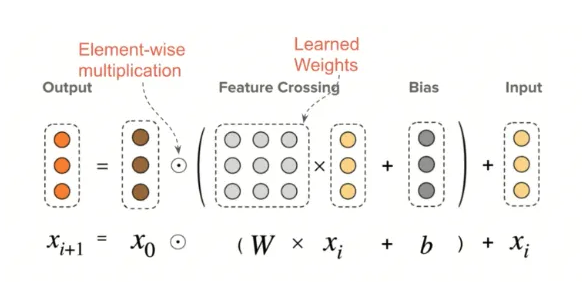
In the above image x0 is the input feature vector. x’ is output of last layer. x0 * x’ * w will perform a weight interaction . Weight matrix will learn which interactions are most important. First we will transform the xi layer (select most important crosses) and then interact it further with input vector to generate crosses of i+1 order.
Intuitive Explanation

In the above examples we have one user and one query feature in input vector (x0). Weight matrix is a binary matrix. The first order feature cross will generate user x query and query x user feature. As we add more layers we would have higher order features.
F: DCN V2 — DCN On Steroids
DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-scale Learning to Rank Systems
With the aim to speed up learning and inference of DCN, the authors of DCN v2 introduces low rank factorization technique to cross feature computation. In DCN we were learning a weight matrix at each layer to transformer input of previous layer before performing Hadamard product with input vector. This process is computationally intensive.

DCN V2 computes low rank factorization of the weight matrix and learns matrix U and V (in the above image) as part of training. This process drastically reduces number of parameters of the model and speeds up training as well as inference.

Part 2 Handcrafting Ranking Model Architecture
In this section we would take learning from part 1 and use them to create ranking model architecture.
A. Baseline Model

In this architecture we have try to divide the model layers into following components
- Input Layer — contains float value features, categorical id based features and embedding based features
- Feature interaction layer : this can be performed in various ways as discussed in earlier posts
- Transformations : Higher layers to transform the interacted features
Dense Features (float value features) transformation
In the baseline model we transform the dense features via a fully connected (FC) layer with non linearity to generate dense representations. The output of this layer is concatenated with feature interaction layer.
Sparse Feature Interactions
We can drive the intuition for this step from Factorization Machines discussed in Part 1.B
In this layer we take pair wise dot product of embeddings of all sparse (id based ) features e.g. user embedding * product embedding, user embedding * brand embedding etc.
After concatenating the output of the above two steps we further transform them to learn generalized representation. Finally a sigmoid unit decides the click probability.
B. Dense Sparse Interactions
In the last architecture we performed sparse feature interactions but skipped dense — sparse interactions. Dense features contain bias information e.g. age, gender of user, price of product, popularity score, trending score etc. of the product. When interacted with sparse features, we can gain valuable higher order features. The idea for this type of interactions was first discussed in DeepFM: A Factorization-Machine based Neural Network for CTR Prediction

C. Dense Gating
As discussed in the above architecture, dense features have very critical information that acts like bias for the model. But given the context, important of different dense features can vary e.g. in Ad ranking model, if ads category is gaming then age of the user can be very relevant dense feature. To provide these features higher weight we will use Dense Gating mechanism.
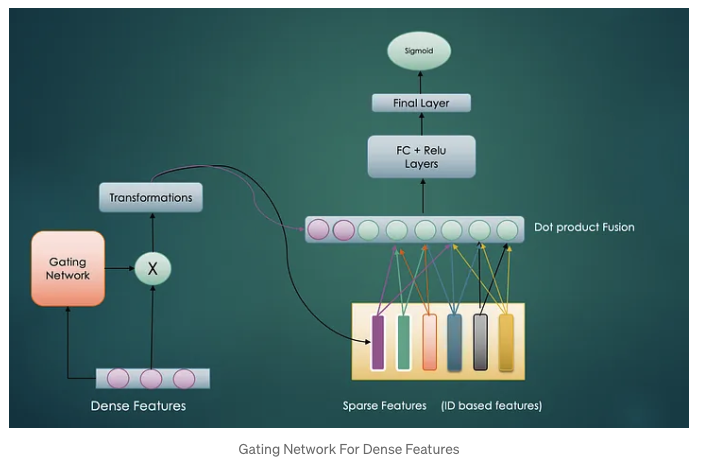
The gating network will learn to select the most important dense features and then transform them to generate dense representation. By introducing the dense gating mechanism, we can control the activation of each dense feature differently before we apply the shared weight matrix.
D. Memorization — Adding feature interaction output to final layer
Final layer is usually considered as an approach to memorize specific patterns for the model (in contrast, deep neural network before the final layer is more about generalization power).

E. Further Optimization
We can perform many other optimizations to the above architecture e.g.
- Increase size of sparse embeddings
- Increase dense feature projection
- Increase Over Arch layer dimensions
- Increase Final layer dimensions
- Layer Normalization
- Position Weighted Features
- Attention Factorization Machines : uDifferent feature interaction might have different importance for the prediction task. (User gender = male) * (User watch history contains genre rock) might be more important than (User gender = male) * (Query Text Embedding)
