

During my time at Facebook Marketplace I worked at a very esoteric problem of semi automating attribute discovery i.e. finding granular attribute values from product titles and description that are not present in the Product Attribute Taxonomy. Each category in e-commerce catalog has a unique set of attribute types and values e.g. Clothing > Men’s > Shirt can have Colors, Size, Pattern, Brand Attribute Types and each attribute type will have given set of values (Size can X, S, M, L, XL etc). These attributes play critical role in Query Understanding Models as well as act as critical features in Retrieval and Ranking Models. So the richer the Attribute Taxonomy is, the better would be customer experience.
At most of the e-commerce companies the current process to find these attributes involves manual analysis of data and other data sets by Taxonomists. The existing approach is a top down approach i.e. for each category Taxonomists would do competitor analysis and create attribute types and their corresponding values relevant to the concerned category.
Some of the drawbacks of manual attribute creation are
- Scalability issues : Hard to keep up with creation of attribute types and values with more and more products/catalog being added to the catalog
- Low Coverage : There is no way to discover attribute values present in out data that corresponds to an attribute type. This often leads to low coverage.
- Rules/Synonyms creation : synonyms for attribute values are manually curated and in the existing pipeline coverage is directly proportional to quantity of synonyms an attribute value has.
The rest of the document would discuss some approaches that can be used to automatically discover attribute values and group similar attribute values that may represent potential attribute type. Furthermore we would try to extract all relevant synonyms for the discovered attributes. This approach is a bottom up approach i.e. we would look at the data first and then come up with a set of attributes.
Attribute Discovery Process
The proposed attribute discovery approach is unsupervised in nature. The procedure broadly involves hierarchical clustering the data and extracting relevant keywords from each cluster. In the next step we would try to further prune and cluster the keywords that are similar to each other. The aim of the proposed approach is to present clusters of high quality keywords from different categories to the taxonomists and thereby save their time and effort. By highly quality we mean keywords that are not only statistically relevant but also define either some property or quality of the core entity described in the category e.g. for category Baby & Kids > Diapering > Cloth Diapers we would want to automatically create a list of following keywords [small, large, prefold, resusable, snap, pocket, inserts, covers, lot, size, liner, organic, bamboo] that defines the properties of diapers and a second list that may contain probable brands associated with clothing diapers e.g. Bumgenius, Thirsties, Grovia, Alva, Panales, Tela. In the final step a Taxonomist can prune or select the proposed keywords.
PART 1 Analysis
Step 1: Product Representation Creation
For the experimentations sake we have only considered product title and description features to create product representation. We used pre trained Hugging Face sentence transformer to generate product embeddings of length 768. Although better representations can be created that can use other product features like image, prices etc.
Step 2: Hierarchical Clustering
In this step we performed Ward Hierarchical Clustering[1] on the 905 X 768 matrix created in the last step.

The above dendrogram plot indicates that there are 4 clusters in the Clothing Diapers Category. In Semi-supervized Class Discovery [2] and PinnerSage: Multi Modal User Embedding Framework For Recommendations[3], researchers at Google and Pinterest respectively have used similar kind of hierarchical clustering approaches to club similar products for further analysis.
Later on we would want to automate the process of detection of optimal numbers of clusters.
A quick look at the word clouds of 1st and 2nd cluster provides a glimpse into different prominent keywords present the corresponding clusters.

Cluster 1

Cluster 2
Step 3: TextRank: Keyword Extraction
This step involves extracting most relevant keywords from the clusters created in last step. We use TextRank[4], a graph based ranking model for text processing. TextRank creates a graph from tokens presents in product titles and descriptions, after certain preprocessing it uses a scoring model to rank nodes in the graph. TextRank[4] provides better results from statistical and lexical analysis based approaches. We tried exploring other methods like EmbedRank[5], that uses embedding based similarity between sentences and the whole corpora but found that TextRank best suits to our use case.
List of most relevant keywords from first cluster (applying stemming and grouping similar tokens)
('insert', ['insert', 'inserts', 'inserted']),
('size', ['size', 'sized', 'sizes']),
('cover', ['covers', 'cover']),
('brand', ['brand', 'brands']),
('lot', ['lot', 'lots']),
('newborn', ['newborn', 'newborns']),
('pocket', ['pocket', 'pockets']),
('small', ['small']),
('new', ['new']),
('prefold', ['prefolds', 'prefold']),
('snap', ['snaps', 'snap']),
('bag', ['bag', 'bags']),
('bumgenius', ['bumgenius']),
('thirsties', ['thirsties']),
('liner', ['liners', 'liner']),
('included', ['including', 'includes', 'included']),
('bum', ['bum', 'bums']),
('bamboo', ['bamboo']),
('white', ['white']),
('reusable', ['reusable']),
('organic', ['organic']),
('velcro', ['velcro']),
('lbs', ['lbs']),
('large', ['large'])
The above mapping provides us a candidate list of attribute values and their corresponding synonyms.
Step 4: Semantic Association Between Important Keywords : Network Based Analysis
After creating an initial list of candidate attribute values, the intuitive next step would be to group so that each group can be defined by an attribute type and further prune the candidate list to get most relevant keywords pertaining to category “Cloth Diapers”.
Example: In the above list “pocket”, “prefold”, “snap”, “size” defines properties of cloth diapers but “velcro” is a property of “pocket”.
In this step we create a graph of tokens extracted in last step based on their proximity in the product titles and descriptions. In this experiment we create an edge between nodes only if the corresponding keywords are within a window size of 1 i.e. adjacent to each other. We use python networx[6] for creating a directed acyclic graph(DAG) of keywords.

The above DAG clearly shows some interesting properties of our attributes.
- The red colored edges show direct associations of “cloth diapers” i.e. core attributes of cloth diapers.
- Connection between Velcro node and Pocket node shows that velcro is an aspect of pocked diapers.
- Similarly color “white” is an attribute of “liner” and “velcro” nodes.
- Two directed edges between Brand and Thirsties creates string association between them implying that Thirsties is a brand.
In similar manner we can make more inferences.
Step 5: Hierarchical Embeddings: Creating Hierarchical Relations Between Nodes
Once we have a DAG of important keywords and a natural next step would be to understand the hierarchy among the nodes. We would want to know the core nodes representing the backbone of the network and their associated satellite nodes.
Some of the ways that didn’t result into meaningful node associations
- PageRank: Apart from generating high ranking nodes, PageRank didn’t provide us any semantic information from the graph structure itself.
- Generating word embedding using FastText[7] and further using embeddings of the extracted keywords for hierarchical clustering.
In this step we generated POINCARE EMBEDDINGS[8] of the nodes of the graph created in last step.
"Poincaré embeddings are a method to learn vector representations of nodes in a graph. The input data is of the form of a list of relations (edges) between nodes, and the model tries to learn representations such that the vectors for the nodes accurately represent the distances between them. The learnt embeddings capture notions of both hierarchy and similarity - similarity by placing connected nodes close to each other and unconnected nodes far from each other; hierarchy by placing nodes lower in the hierarchy farther from the origin, i.e. with higher norms. The main innovation here is that these embeddings are learnt in hyperbolic space, as opposed to the commonly used Euclidean space. The reason behind this is that hyperbolic space is more suitable for capturing any hierarchical information inherently present in the graph. Embedding nodes into a Euclidean space while preserving the distance between the nodes usually requires a very high number of dimensions."[9]

We generated 2 D representations of the nodes using gensim.models.poincare[10]. The nodes near to the origin represents the root nodes of the graph. Node “clothing diaper” is at coordinate 0,0. thereby suggesting that it is the root node (key topic) of the graph. Nodes at the periphery like lbs, bum, new etc. are the leaf node and much down in the hierarchy i.e. not directly relevant to the root node “cloth diaper”.
To fetch the key attributes of clothing diapers we extract the nearest neighbors of the root node. The list below shows nearest neighbors with their corresponding
[('cloth diaper', 0.0),
('small', 0.1365535033774657),
('large', 0.17949012971429448),
('prefolds', 0.20087067143255224),
('reusable', 0.22612112692088746),
('inserts', 0.29712060251440736),
('bumgenius', 0.30584862418124015),
('covers', 0.3563740496401796),
('lot', 0.3919719432521571),
('pocket', 0.409106234142296),
('size', 0.4996583982212509),
('liner', 0.621093919540953),
('snap', 0.7515983205641947),
('organic', 0.8492109718887274),
('bamboo', 0.851353947350201)]The above list shows some high quality candidates for attribute values associated with cloth diapers.
Step 6: Key Phrase Extraction And Text Summarization
Till now we have tried to extract important keywords descriptive of “clothing diapers” category. Another highly effective way to get a good idea of the context and use of different keywords w.r.t “clothing diapers” in all the product titles and descriptions is by text summarization. We used Spacy pytextrank[11] that creates a graph similar to keyword TextRank graph created in step 3 but uses phrases instead of keywords as graph nodes.
Summarization tries to paint a complete picture of the different topics discussed in the text. In our case the list below consists of all attributes and brands present in the clothing diaper category.
The tokens marked in bold represents probable brand names.

Part 2 – Multi Stage Approach : Brand Extraction
The first phase would generate a broad list of keywords using an ensemble of unsupervised methods. As we have seen earlier that output of keyword extraction algorithms is often noisy as well as contain generic keywords like “price”, “shipping”, “FCFS” etc. that are not category specific. Once a candidate set is generated we would like to apply a set of rules like blacklist keywords, noun/ pronoun detection, named entity detection and other heuristics to prune candidate list. Ideally a classification model should further classify the pruned set of candidates into probable attribute value or not. We would discuss this discriminator based methods in next part of this blog series.

Rest of the document would deal with explanation of the individual component described in the above architecture.
The proposed architecture comprise of two key components
I. Candidate Generation

From the plethora of approaches discussed in [12] and [13], the best methods of unsupervised keyword extraction are graph based. In step 6 (Keyword Extraction And Text Summarization) we have already seen that although the results of TextRank comprised of noise and generic keywords, the recall of category specific keywords was high.
In the first phase we can just run some out of shelf keyword extraction algorithms like the one discussed below and take a union of keywords set generated by them.
A. Graph Based Keyword Extraction Methods
Majority of the popular unsupervised approaches use graph based centrality measures like Eigenvector centrality and PageRank to find relevant keywords from co-occurence token graph of concerned text. Complex Network based Supervised Keyword Extractor[23] shows that although various centrality based metrics effectively captures node importance, however probability density distribution of strength for keywords and non-keywords for the training set prepared during their study shows overlapping areas near high strength values. The overlap indicates that strength alone is not an accurate discriminator between keywords and non-keywords. The experimental results of [23] validates our findings of extracting large number of false positive keywords when we used unsupervised methods like TextRank that uses PageRank bases graph centrality metric.
Graph Centrality Metrics
- Eigenvector Centrality : It quantifies a node’s embedded-ness in the network while recursively taking into account the prestige of its neighbors.
- PageRank : It computes the prestige of a node in the context of random walk model.
- PositionRank: An extension of PageRank that is based on the intuition that keywords are likely to occur towards the beginning of the text rather than towards the end.
- Coreness: Coreness is a network degeneracy property that decomposes network G into a set of maximal connected subgraphs, such that nodes in each subgraph have degree at least k within the subgraph. Coreness of a node is the highest core to which it belongs.
- Clustering Coefficient : Clustering coefficient of a node indicates edge density in its neighborhood. It is a local property.
- Strength of a node : Strength(weighted degrees) of a node measures its embedded-ness at local level.

Graph Based Keyword And Key Phrase Extraction Algorithms
- TextRank[4]
- Only use nouns and adjectives as nodes in the graph
- no edge weights for keyword graph
- SingleRank[14]
- incorporates weights to edges, the co-occurrence statistics are crucial information regarding the contexts
- RAKE [15] (Rapid Automatic Keyword Extraction)
- that utilizes both word frequency and word degree to assign scores to phrases
- SGRank [16] and PositionRank [17]
- stage 1
- utilize statistical, positional, and word co-occurrence information
- considers only noun, adjective or verb
- takes into account term frequency conditions
- stage 2
- the candidate n-grams are ranked based on a modified version of TfIdf
- stage 3
- the top ranking candidates are re-ranked based on additional statistical heuristics, such as position of first occurrence and term length
- stage 4
- the ranking produced in stage three is incorporated into a graph-based algorithm which produces the final ranking of keyphrase candidates
- stage 1
B. Topic Based Methods
- TopicRank [18]
- preprocesses the text to extract the candidate phrases. Then, the candidate phrases are grouped into separate topics using hierarchical agglomerative clustering
- In the next stage, a graph of topics is constructed whose edges are weighted based on a measure that considers phrases’ offset positions in the text.
- TextRank is used to rank the topics and one keyphrase candidate is selected from each of the N most important topics
- Salience Rank [19]
- It runs only once PageRank, incorporating in it a word metric called word salience Sα (w), which is a linear combination of the topic specificity and corpus specificity of a word (the last can be calculated counting word frequencies in a specific corpus). Intuitively, topic specificity measures how much a word is shared across topics (the less the word is shared across topics, the higher its topic specificity)
C. Graph-based Methods with Semantics
“The main problems of the topic-based methods are that the topics are too general and vague. In addition, the co-occurrence-based methods suffer from information loss, i.e., if two words never co-occur within a window size in a document, there will be no edges to connect them in the corresponding graph-of-words even though they are semantically related, whereas the statistics-based methods suffer from information overload, i.e., the real meanings of words in the document may be overwhelmed by the large amount of external texts used for the computation of statistical information.”[13]
Method 1 – Distant supervision using knowledge graphs[20]:
a. Nouns and named entities (keyterms) are selected and grouped based on semantic similarity by applying clustering
b. The keyterms of each cluster are connected to entities of DBpedia
c. For each cluster, the relations between the keyterms are detected by extracting the h-hop keyterm graph from the knowledge graph, i.e., the subgraph of DBpedia that includes all paths of length no longer than h between two different nodes of the cluster.
d. Then, all the extracted keyterm graphs of the clusters are integrated into one and a Personalized PageRank (PPR)[6] is applied on it to get the ranking score of each keyterm.
Method 2: WikiRank[21] is an unsupervised automatic keyphrase extraction method that tries to link semantic meaning to text
a. Use TAGME[8], which is a tool for topic/concept annotation that detects meaningful text phrases and matches them to a relevant Wikipedia page
b. Extract noun groups whose pattern is zero or more adjectives followed by one or more nouns as candidate keyphrases
c. A semantic graph is built whose vertices are the union of the concept set and the candidate keyphrase set. In case the candidate keyphrase contains a concept according to the annotation of TAGME an edge is added between the corresponding nodes
d. The weight of a concept is equal to the frequency of the concept in the full-text document.
e. The score of a concept c in a subgraph of G to be
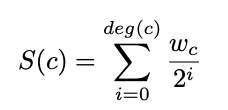
II. Candidate Pruning

Generic Keywords Filtering
The rule set would comprise of blacklist of keywords that are generic and doesn’t corresponds to any specific characteristic of product category. We can keep a global as well as category specific keyword list. Example keyword blacklist
keyword_blacklist = ["hola", "pick", "pickup", "cash", "collect", "locate", "work", "contact", "use", "locat", "news", "good", "total", "valu", "complete", "list", "sold", "know", "limit", "want", "complete", "near", "offer", "new", "date", "nice", "day", "interest", "ship", "sell", "item", "price", "need", "need", "link", "like", "sale", "includ", "free", "look", "condit", "ship", "www", "need", "great", "machine", "come", "sale", "item", "sell", "ask", "com", "like", "avail", "beauti", "excel", "look", "best", "thank", "meet", "came", "help", "got"]
Apart from creating a blacklist we can also use statistical analysis to study the spread/dispersion of a keyword across categories. A keyword with low inverse document score or coverage across categories should be automatically filtered.
Another set of rules would be extraction rules that would help us extract brands. These rule set would involve simple pattern matching components that would help us create a weak supervision system on the lines of how SNORKEL[22] works.
For brand extraction we perform following steps and then apply the following set of weak supervision rules
Heuristics Based Filtering
- Filter output candidates based on POS Tagging and NER Tagger output
- is candidate noun or pronoun
- is NER label ORG
- is first character upper
- Statistical Pruning
- is length less than 20 and greater than 3
- Filter candidates based on block word list
- Filter candidates based on dictionary check
- Filter Candidates based on syntactic check
- is candidate ASCII
- is not all numeric
- is not in english dictionary
One of the foremost drawback of using a totally unsupervised method for keyword extraction is that we don’t learn from our mistakes once we get feedback on extracted keywords from a Taxonomist. Another issue is that without a model based approach for keyword extraction, we miss out on using approaches like Active Learning that can guide us in creating better training data and hence a better feedback loop to get the contentious data points labeled. The unsupervised keyword extraction techniques are not domain sensitive i.e. they are not tunable to adapt to the data domain or topic and spits out lots of generic keywords that are not important for the domain under consideration. Also the share number of candidates generated are hard to get labeled, so we definitely need a mechanism to rank them in order of importance and get a feedback from domain experts.
Next post discusses semi supervised approaches to improve the attribute extraction process using Graph Neural Networks.
References:
- Ward’s Hierarchical Clustering Method: Clustering Criterion and Agglomerative Algorithm
- Semi-Supervised Class Discovery
- PinnerSage: Multi-Modal User Embedding Framework for Recommendations at Pinterest
- TextRank: Bringing Order into Texts
- Simple Unsupervised Keyphrase Extraction using Sentence Embeddings
- NetworkX: Network Analysis in Python
- Enriching Word Vectors with Subword Information
- Poincaré Embeddings for Learning Hierarchical Representations
- https://rare-technologies.com/implementing-poincare-embeddings
- https://radimrehurek.com/gensim/models/poincare.html
- https://spacy.io/universe/project/spacy-pytextrank
- A Review of Keyphrase Extraction
- Kazi Saidul Hasan and Vincent Ng, Automatic Keyphrase Extraction: A Survey of the State of the Art, Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics
- Wan, X. and Xiao, J. (2008) Single document keyphrase extraction using neighborhood knowledge. In Proceedings of the 23rd AAAI Conference on Artificial Intelligence, AAAI 2008, Chicago, Illinois, USA, July 13-17, 2008, 855–860. URL: http://www. aaai.org/Library/AAAI/2008/aaai08-136.php.
- Rose, S., Engel, D., Cramer, N. and Cowley, W. (2010) Automatic keyword extraction from individual documents. Text Mining: Applications and Theory, 1–20. URL: http://dx.doi.org/10.1002/9780470689646.ch1.
- Danesh, S., Sumner, T. and Martin, J. H. (2015) Sgrank: Combining statistical and graphical methods to improve the state of the art in unsupervised keyphrase extraction. In Proceedings of the Fourth Joint Conference on Lexical and Computational Semantics, Denver, Colorado, USA., June 4-5, 2015, 117–126. URL: http://aclweb.org/anthology/S/S15/S15-1013.pdf.
- Florescu, C. and Caragea, C. (2017b) PositionRank: An unsupervised approach to keyphrase extraction from scholarly documents. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017, Vancouver, Canada, July 30 – August 4, 2017, Volume 1: Long Papers, 1105–1115. URL: https://doi.org/10.18653/v1/P17-1102.
- Bougouin, A., Boudin, F. and Daille, B. (2013) TopicRank: Graph-based topic ranking for keyphrase extraction. In Proceedings of the 6th International Joint Conference on Natural Language Processing, IJCNLP 2013, Nagoya, Japan, October 14-18, 2013, 543–551. URL: http://aclweb.org/anthology/I/I13/I13-1062.pdf.
- Teneva, N. and Cheng, W. (2017) Salience rank: Efficient keyphrase extraction with topic modeling. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017, Vancouver, Canada, July 30 – August 4, Volume 2: Short Papers, 530–535. URL: https://doi.org/10.18653/v1/P17-2084.
- Shi, W., Zheng, W., Yu, J. X., Cheng, H. and Zou, L. (2017) Keyphrase extraction using knowledge graphs. Data Science and Engineering, 2, 275–288. URL: https://doi.org/10.1007/s41019-017-0055-z.
- Yu, Y. and Ng, V. (2018) Wikirank: Improving keyphrase extraction based on background knowledge. In Proceedings of the 11th edition of the Language Resources and Evaluation Conference, LREC 2018, 7-12 May 2018, Miyazaki (Japan), 3723–3727. URL: http://www.lrec-conf.org/proceedings/lrec2018/pdf/871.pdf.
- Snorkel: Rapid Training Data Creation with Weak Supervision
- Complex Network based Supervised Keyword Extractor

Pingback: Graph Neural Networks Based Attribute Discovery For E-Commerce Taxonomy Expansion | smashinggradient