

Consider a typical e-commerce product. It would have a variety of content specific features like product title, brand, thumbnail etc and other engagement driven features like number of clicks, click through rate etc. Any machine learning model ingesting features of this product(e.g. product ranker, recommendation model etc.) would have to deal with the problem of merging these distinct features. Broadly speaking we can divide these features in following categories
- Dense Features
- Counter : #times clicked in k days/hours
- Ratio : CTR of entity
- Float: Price
- Sparse Features
- Category Id
- Listing id : [ids of last k products clicked]
- Rich Features
- Title Text Embedding
- Category/Attributes Embedding
In a Neural Network if we step beyond the input layer, a common problem faced is around fusing (merging) these features and creating a unified embedding of the entity (e-commerce product in our case). This unified embedding is then further transformed in higher layers of the network. Considering the variety of features (float value features, embedding based features, categorical features etc), performance of the model depends on when and how we process these features.
In rest of the post we would discuss various feature fusion techniques.
Embedding Feature Fusion Techniques
For the sake of simplicity we would first consider the case of how to handle multiple embeddings in the input feature layer. Later on we would include architectural techniques to merge dense (float value features). As an example if we are building a music recommendation model, one of the input to the recommender may be embeddings of last k songs listened by the user or embeddings of genres of last k songs listened. Now we would want to fuse(merge) these embeddings to generate a single representation for this feature. Next section would discuss techniques to combine these embeddings in the input layer and generate a unified embedding.
Method 1 – Concatenate And Transform
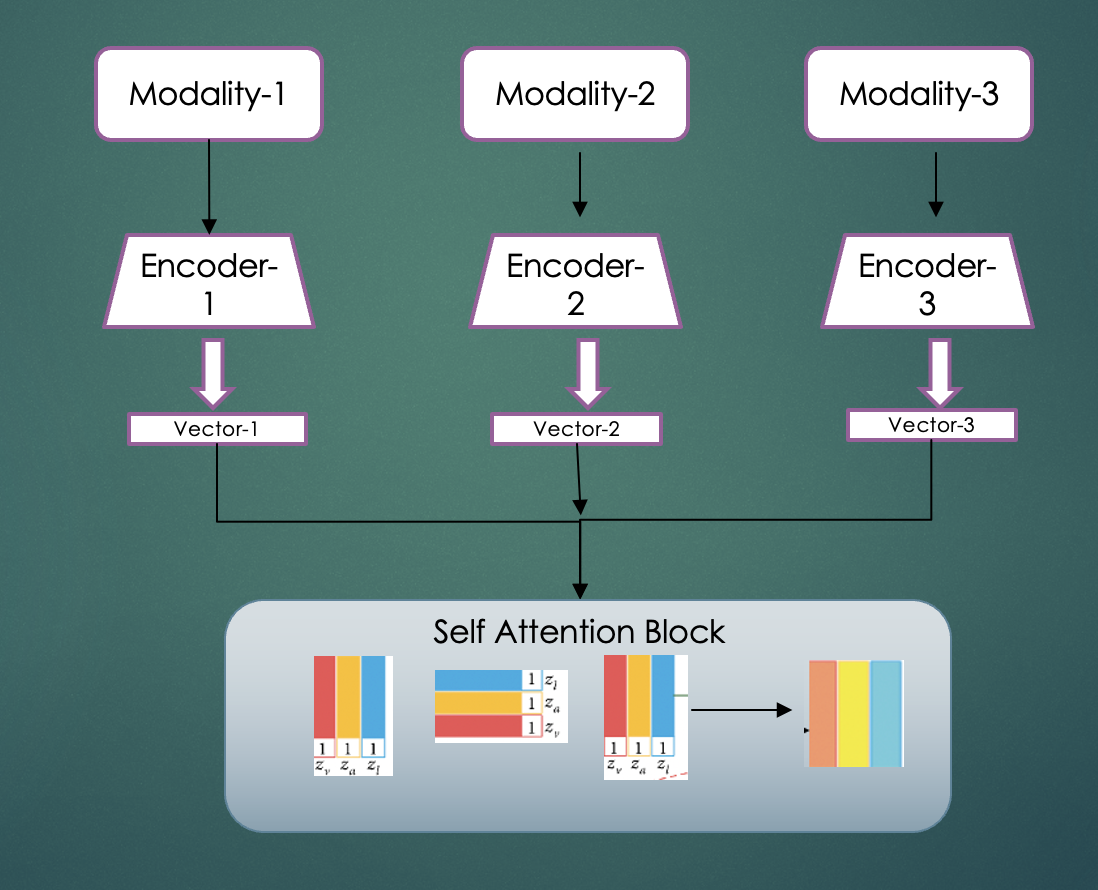
In the diagram below, input layer can have text, images and other types of features. Respective encoder would process the corresponding input (e.g. pre-trained Resnet can generate image embedding, pre trained BERT can generate text embedding etc) and generate an embedding. These embeddings are represented as vector-1, vector-2 and vector-3.
In concatenation based fusion technique we would concatenate embeddings belonging to each modality and then pass it through a fully connected network.

Method 2 – Pooling
Another light weight technique is use techniques like mean and max pooling. In the image below, Youtube session recommender is fusing embeddings of watched videos in a session using average of their embeddings.

Method 3 – Pair Wise Dot Product
In this method we would take pairwise dot product of each embedding (vectors in the image below). After the pair wise dot products we would further use MLP (or Full connected) layers to transform it.


One of the drawback of this technique is its computational complexity. Due to quadratic computational complexity, the number of dot products grow quadratically in terms of the number of embedding vectors. With increasingly input layer, the connection of dot products with fully connected layer can become an efficiency bottleneck and can constrain model capacity.
To overcome this issue we can resort to Compressed Dot Product Architecture discussed in the next section
Method 4 – Compressed Dot Product Architecture

In the above figure we have showcased pairwise dot product fusion as matrix multiplication. Consider X as a matrix of feature embeddings. Here we have 100 features and each feature embedding is of length 64. Pair wise dot product can be view as a product of feature matrix and its transform.
The compression technique exploits the fact that the dot product matrix XXT has rank d when d <= n, where d is the dimensionality of embedding vectors and n is the number of features.
Thus, XXT is a low rank matrix that has O(n*d) degree of freedom rather than O(n2). In other words, XXT is compressible. This is true for many current model types that have sparse input data. This allows compression of the dot product without loss of information.

- X is an n*d matrix of n d-dimensional embedding vectors (n=100;d=64).
- Per techniques described herein, instead of calculating flatten(XXT), flatten(XXTY) is calculated.
- Y is an n*k matrix (in the example k=15).
- Y is a learnable parameter and is initialized randomly.
XXT would lead to n * d * n operations, where as dot product compression XXTY would take O(n * d * k) operations (k is very less than n).
Y is a learnable parameter and is initialized randomly. Y can be learnt, alongside other parts of the model. The projection through Y significantly reduces the number of neurons passing to the next layer while still preserving the information of original dot product matrix by exploiting the low rank property of the dot product matrix.
One of the drawback of this approach is that learned matrix Y becomes independent of the input. It would have same values for all inputs. To resolve this issue, we can use attention aware compression (please refer to Dot Product Matrix Compression for Machine Learning for more details).
Method 5 – Attention Fusion
In this approach we follow the self attention logic to fuse different embeddings.
Method 6 – Tree based Fusion
In this technique we concatenate the feature embeddings and provide them as a single input to a Tree Ensemble Model e.g. Boosted Trees or GBT. This model will be separately trained from the main neural network. In this phase we would take output of leaves of each tree in the ensemble. In the image below these are depicted as h1, h2 etc. The fused (transformed) embedding will be concatenation of the output of leaves (h1 + h2 + ..). This will be provided as input to the main neural network. On a high level this acts as a non linear transform of input features.

Dense (Float) Features Fusion
The special case for feature fusion is for float value features. Unlike embedding based feature fusion, here we have just one vector of float features (e.g product price, click through rate, add to cart rate etc.). For handling dense features we would pass them through a fully connected layer with non linearity. This will lead to a transformed representation that would either concatenated or interacted with sparse fused features.

Baseline Model
An example architecture for a baseline model is described below

In this architecture we are first performing fusion of dense features. Separately sparse features (or embedding features) will have dot product fusion in a separate layer. As next step we are concatenating the fused vector of dense and sparse vectors in the interaction arch. In the next part of the network we are performing transformations over the concatenated feature vector.
Dense Sparse Feature Fusion
The last piece of the puzzle is how to interact the dense features and sparse features. Till now we have seen embedding based feature fusion (let’s say via dot product fusion) and dense (float value features) fusion. In this section we would explore how to interact (fuse) them together.

For dense-sparse interactions we would first generate an intermediate representation of the dense features via performing a non linear transform. Then we would perform following two steps
- Concatenating transformed dense feature representation to interaction layer
- Stacking the transformed dense feature representation with embedding inputs
In this way the dense transformed representation (output of FC + Relu layer) would take part in dot product fusion, hence it will interact with the individual embeddings of the input layer. Since dense features contain bias information (e.g. CTR or number of clicks provide bias about product performance), we would want to preserve this information. Hence in a residual connection kind of way we concatenate the transformed dense representation with the output of dot product fusion.

Pingback: Neural Ranking Architectures | smashinggradient
Pingback: Revamping Dual Encoder Model Architecture: A layered approach to fuse multi-modal features and plug-and-play integration of Encoders | smashinggradient