
Introduction:
The journey of a search query through e-commerce engineering stack can be broadly divided into following phases, search query text processing phase, retrieval phase where relevant products are fetched from indexer and the last but not the least, product re-ranking phase where a machine learning ranking engine re sorts the products primarily based on combination of KPIs like click through rate, add to cart rate, checkout rate etc. The focus of this post would be primarily on the first phase i.e. query text processing via a Query Understanding Service (QUS). I would be discussing the applications and working of QUS in e-commerce search. QUS is one of the most critical service needed to resolve user query and find the key search intent. Among the plethora of machine learning(ML) services working across the engineering stack in any e-commerce company, QUS is usually the first to hold the fort and acts as the backbone ML service in pre retrieval phase.
When a user enters a query in the search box, the first step is to ingest that raw text and generate some structured data from it. The objective here is to find as much relevant information from the query as possible and retrieve the most relevant results for the user.

The search query in e-commerce can contain many clues that can guide us in finding results pertinent to user’s intent. A query like “levi black jeans for men” consist of a un-normalized brand name “levi”, gender “men”, product type “jeans”, color “black” and top level taxonomy category of the query can be Clothing & Accessories. The aim of QUS is to find these attributes, normalize them (levi => Levi Strauss & Co, mens => Men etc.) and send this information to retrieval endpoint to fetch relevant results. QUS would comprises of an ensemble of sub services like query category classification service, query tagging service, attribute normalization service etc. In the case of long tail queries(queries that are not too common and results in either very limited products or null results) the output of QUS can be further used to relax by rewriting it, this process is known as query relaxation. Furthermore we can also expand the query (query expansion) where we can show user results which are near similar to search query e.g. if user search for “light blue tee”, we can expand the results set where color can be either light blue, blue or violet. Also in case of brand sensitive queries, the result can be expanded to near similar brands to provide user exposure to available alternatives in your inventory.
Common Issues
QUS will help move search beyond raw keyword match. In a world without QUS following issues can occur if we depend on pure SOLR retrieval
- Wrong product categorization : queries like “hershey cocoa powder” that belong to Grocery category can retrieve fashion products since it has the word “powder” in it.
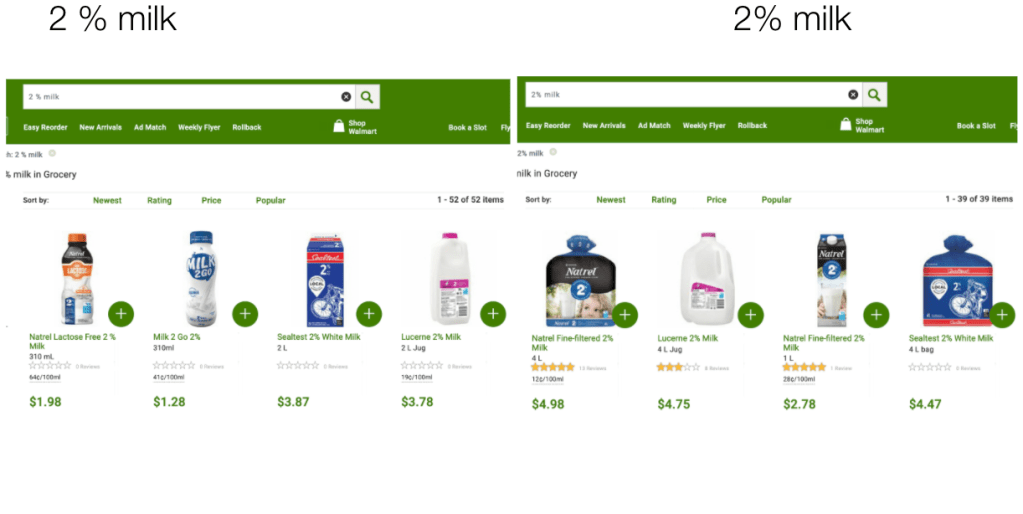
- Retrieval Sensitivity :
- Queries like “office desk wooden” vs “office desk wood”, “halloween costumes for girls” vs “halloween costumes girls” can result in different results although they have the same search intent.

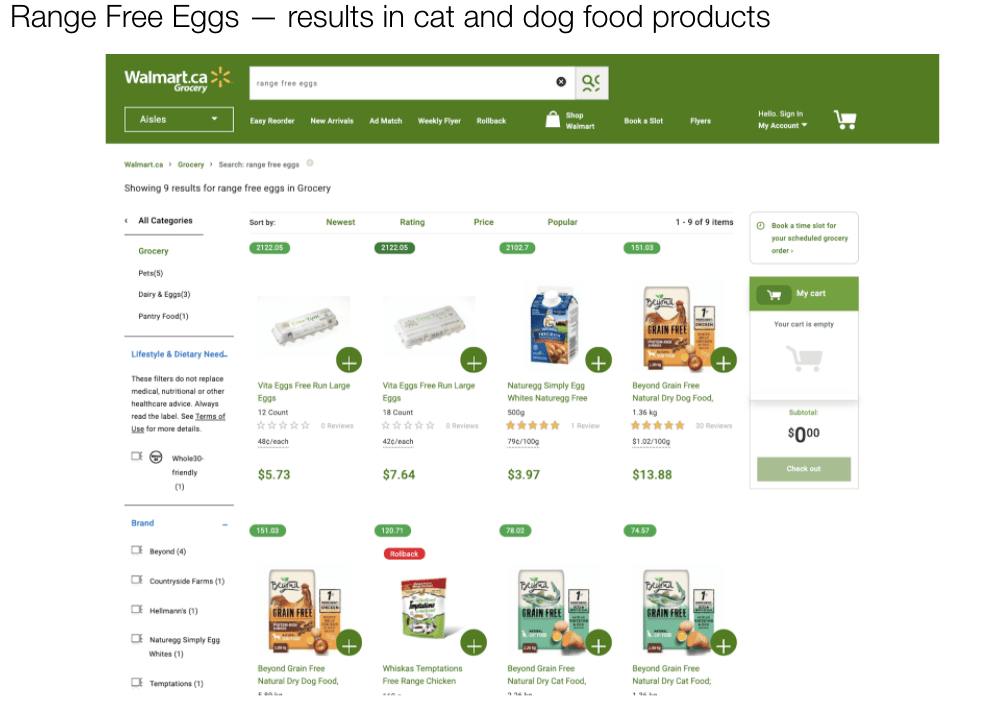
B. Solr Provides equal weightage to all the tokens. This may result in a situation like the following where the tokens “range” is getting equal weight as “eggs”. Hence the result set includes “range free chicken”.
3. No query relaxation: too narrow queries are mostly unresolved e.g. “fleece queen size sheets” can return blankets – query should be relaxed to “queen size sheets”
4. Price Agnostic Search: Another feature of QUS is be to extract price information from the query, this either can be done by using either a set of regular expressions or using tagger + normalizer.

5. Unresolved Brand Variants: For queries like “coke six pack” vs “coca-cola six pack” results can be different.

Search Phases
We can divide the e-commerce search process in two phases

Post Retrieval :
This phase is concerned with the retrieved relevant results corresponding to the query. It is here where we rank the results, add recommendation, add sponsored products to the final list of results.

Pre Retrieval :
This is the phase where we haven’t yet retrieved results from backend indexing engine yet. The only information we got to deal with is the raw user query. Usually this phase comprises of following components (can be separate microservices)
Spell corrector
Intent Detection

Query Classifiers
Category Classifier: This service would classify the query into leaf level categories corresponding to the catalog structure/taxonomy. The output of this service would be a set of leaf level categories. Solr can either filter the results on the basis of predicted set of categories or boost the results for products belonging to predicted category set.
Product Type(PT) Classifier: Usually taxonomies are hierarchical in nature e.g. Under top level Clothing & Accessories category you would have Shirts at level 2 and Men/Women/Children at level 3, formal/casual at level 4 etc. Due to noise in catalog content and semantic issues in catalog structure (near similar leaf categories under different L1s e.g. tea can be in Grocery as well as Office > Pantry items) it is usually better to classify the query into flat hierarchy Product Types e.g. in the context of last query PT would be just Shirts, if query is iphone 9 charger, PT would be “Phone Chargers”
Query Tagger
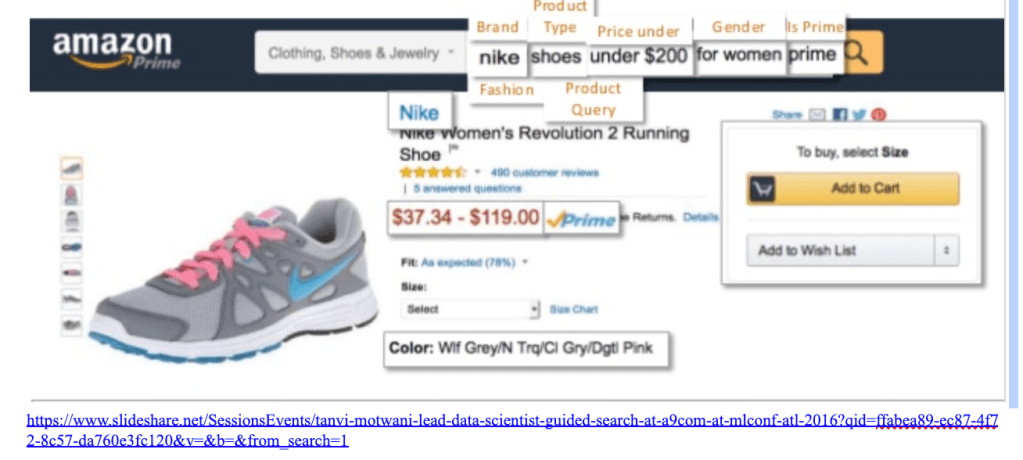
Just like query category classifier and query product type classifier query tagger is another component of QUS but unlike them it works on tagging individual tokens in a query rather than categorizing the whole string.
The aim here to successfully detect customers intent and improve retrieval by finding tokens in the query that contribute to key product being searched by customer, brand, gender, color, size, price range etc. This would help us in
- refining the retrieval in a faceted manner
- resolving long tail queries
- query rewriting and query relaxation
- product promotion / recommendation
Architecture: Bidirectional LSTM-CRF Models for Sequence Tagging Tutorial : https://guillaumegenthial.github.io/sequence-tagging-with-tensorflow.html
Tagger Attributes
Broadly speaking there are two types of attributes, namely global and local. Local attributes are highly specific to particular leaf categories e.g. attributes for Home>Furniture>Table would have attribute key/values like
| Top Material | Engineered Wood |
| Color | Espresso |
| Material | Particle Board |
| Furniture Finish | Espresso |
Since each leaf level category can have specific attributes that are not applicable to other categories, we can end up with a large number of local attribute key/value pairs. That’s why it is better to not to use Tagger to detect these attributes since we would face performance issues in scaling the tagger to these many attributes.
On the contrary there are other set of attributes that are global in nature i.e. they are not focused on any particular category e.g. size can be found in clothing, in furniture, appliances etc. Although the values of these attributes can be category specific e.g. size in clothing can take values like XS, S, M, L etc. while size in home appliances >Microwave category could have valid size values as Compact, Mid-Sized, Family Size etc. They are present across categories or at least in bunch of categories. It is better to use a tagger to detect these attributes. The table below comprises of what we call as global attributes.
| Attribute Key | Description | Attribute Value |
| Brand | Brands are companies and their subsidiaries that offer product | sony, philips, great value, coke etc. |
| Gender | men, boys, women, unisex, girl etc. | |
| Color | Specified colors, also includes materials that represent colors such as gold, silver,and bronze | |
| Character | Characters are recognizable entities that exist in multiple Brands and Product Lines | Batman, Golden State Warriors, Taylor Swift, UCLA Bruins etc. |
| PT Descriptor | Features pertaining to the product as well as media titles | with shelves, led lightbulbs, round dining table |
| Product Line | Product lines from brands | playstation, sonicare, air jordans etc. |
| Miscellaneous | All other relevant tokens including: themes, versions, years, and model numbers | star wars, 2013, paris, ucla, in-store, highest rated etc. |
| Price | $, dollars, bucks, sale, clearance | |
| Age | a. Age Value – Numeric value for age (e.g. 8, 12) b. Age Unit – Context for defining value (e.g. month, year) c. Age Type – Qualitative measurement for age (e.g. baby, teenage, elder, young, jr) | |
| Size | a. Size Value – Numeric value and word representation for sizing (e.g. 3, 120, double) b. Size Unit – Context for defining size (e.g. oz, lb, gb) c. Size Category – Grouping for size units (e.g. weight, volume, length, diameter) d. Size Type – Qualitative measurement for size (e.g. small, medium, large, 4xl, mini, giant, tall, short, wide, slim) | |
| Quantity | a. Quantity Value – Numeric value for quantities b. Quantity Unit – Context for defining quantity (e.g. piece, sheets) c. Quantity Type – Qualitative measurement for quantity (e.g. value size, bulk, set) |
Attribute Normalization
Once the tagger detects a mention in query and tags individual tokens the next step involves normalizing these tokens. For attributes types like color, normalization is pretty straight forward e.g. {red, light red, pink, .. etc} can be mapped to one color family with normalized name RED, similarly for price too we can create a standardized denomination using a set of regular expressions. With normalization we are aiming to standardized the attribute key/value pair w.r.t the values in catalog. Here the prior requirement is that products in catalog would have canonicalized values for attributes e.g. all men shirts would have size attribute mapped to only a predefined values {XS, S, M, L, Xl, XXL ..}. Now once we detect size attribute in a query like “mens small checked shirt”, the next step is to normalize the size token “small” to normalized attribute value in catalog “S”. This would help us in either making a faceted query to SOLR or boost products in retrieval where size attribute is “S”, thereby enhancing the retrieval quality.
Numerical attributes like price, quantity (e.g. 1 gallon milk), Age (toys for 8-12 years old) can be handled with regular expression driven approach. Once we detect category and product type of a query, we can apply set of regular expressions applicable for only those categories and PTs to extract numerical attributes e.g. for query like “2 gallon whole milk”, the category can be “Grocery>Milk>Whole Milk” and PT can be Milk, once we know these values we can apply a set of regular expression created exclusively to handle the grocery/milk quantity/amount normalization. The following set of queries have price attribute values as 20 that can be easily extracted using a couple of regular expressions.
a. “tees under 20”
b. “tees under $20”
c. “tees under 20 dollars”
d. “tees under 20 usd”
Overall attribute normalization can be achieved using following approaches
- Regular Expressions based methods
- Rule based methods
- This is a simple yet very effective approach. Before jumping to nlp based methods a good way to get some quick wins and draw a performance baseline is to manually create rules for normalization.
- A sql like table can be created with each unnormalized attribute mapped to its normalized variant
- A simple lookup in the table can generate normalized attribute values.
- Classification Based Approach:
- The key drawback of the rule based approach is that it is not scalable. It would too much manual effort to analyze the queries and find varied patterns in them and create explicit rules to map them to normalized values.
- But the last approach would provide us a labeled data set to work with i.e. attribute values mapped to their canonicalized versions.
- The above data set can be used to create an attribute classifier. The difference between this and category classifier that I mentioned earlier is that here we would be classifier the tagged mention (e.g. Product Line) and in the earlier we were classifying the whole query string.
- Entity Linking based approach
- Entity linking is wholesome topic that I plan to write about in a separate post. But to provide gist of the idea Entity Linking is a process to detect mention strings in a text that may correspond to names entities (like tagging finds mentions and tags them to attribute keys like Brand, Size etc.) and then tries to map them to the entities in knowledge base. This method can be useful while trying to detect brands in query as well as in product title and description.
- Although there are neural architectures that can detect the mention string and then link the mention to the best candidate entity, in the next section we would discuss a much similar model based approach.
Entity Linking Based Brand Normalization
Let’s say we have a mention string tagged as Brand in the search query. The entity linking task can be broken into two steps: candidate generation and candidate ranking. Candidate generation means fetching normalized brand candidates that are syntactically or semantically similar to the mention string, e.g for search query “paw-patrol fire truck”, the tagger would generate mention for Brand as “paw-patrol” and the candidate generation phase can find a set of syntactically similar brands from catalog for category Toys. Traditionally an information retrieval based approach for candidate generation has been used like BM25, a variant of TF-IDF to measure similarity between mention string and candidate brands and their description. Once we have a set of candidates we can rank them in the Candidate ranking phase.
A context aware ranking can be done by using the left span of mention, mention string, right span of mention as separate inputs to a model. We can create a model to score the contextual similar of a mention string to description of a brand. For getting description of brands(and hence their representations we can either create a custom dataset or get brand pages from wikipedia and learn a representation for them using the title, introduction of the brand).
In Learning Dense Representations for Entity Retrieval authors uses model architecture similar to sentence similarities architecture to put the entity description and mention description representations near each other in the same domain. Furthermore this kind of approach is highly preferable since the brand representations can be pre computed and since in this architecture there is no direct interaction between the encoders on each side, we can just compute the contextually aware representation of the mention string and take a dot product between it and pre computed brand representations. This enables efficient retrieval, but constrains the set of allowable network structures. The image is from the mentioned publication depicting how the components from the query string and entity description can be used to find similarity between the two.

Brand Resolution In A Noisy Catalog
It may happen that brand names are not normalized in the catalog. In this case some brand e.g. Coca-Cola can be referred by different products in catalog using different variants e.g. coke, coca cola, coca-cola, coca + cola etc. Here we can’t normalize brand in query since brand names in catalog aren’t normalized. So instead of canonicalizing the brand in query we should aim to fetch products that refer to any variant of the searched brand.

A simple yet handy way to canonicalize brand names in queries would involve following steps
- Parse the catalog to create a mapping of product type : list of available brand
- E.g. coffee maker : [black decker, black & decker, black and decker, black + decker, Mr. Coffee, Keurig, …..]
- Use Product Type classifier to get the query PT
- Use query tagger to get the token/tokens tagged as B-BR and I-BR
- Now match the tagged tokens with list of brands corresponding to the predicted product type and use string similarity approaches to select candidate brands
- Trigram-Jaccard
- Levenshtein Edit Distance
- JaroWinkler
- FuzzyWuzzy
Example:
For a query like “coffee maker black n decker” the predicted Product Type can be “Coffee Maker” and mention string tagged as brand can be “black n decker”. A lookup in PT to brand list map can return list of valid brand variants in catalog for PT “Coffee Maker” as [black decker, black & decker, black and decker, black + decker, Mr. Coffee, Keurig, …]. Now by using edit distance of either 1 or 2 to we can find candidate brands from brand list mapped to product type coffee maker as [black decker, black & decker, black and decker, black + decker]. Later on Solr can boost all these brands while retrieving the results for this query. In this approach we don’t even needs brands to be normalized in the catalog since we can boost all variants in one go.
Connecting the Dots

Once QUS fetches all the key insights from the query, the results are forwarded to SOLR. The prerequisite is that catalog is indexed with separate dimensions for Category, Brand, product type etc. For retrieval we can use a weight based scheme where higher weight based boost is provided to predicted categories, product types, brands etc. For attributes like category and PT we can even make a faceted search call while adding boosts for predicted brand, product line, size etc. Furthermore we can also add a relaxed secondary query to the main query so that the recall can be high. This will help in resolving long tail queries and null result queries. The product ranker layer can take care ordering the relaxed query supplemental results w.r.t to products returned from main query. More advanced techniques like creating a separate optimization service to predicts weights for attributes to be boosted based on user query can further enhance the relevance of returned results e.g. for clothing query the SOLR weight prediction algorithm can provide more weights to brand and price rather then style/pattern.
